
Login to Mockaroo to generate 1000 records of Random Data, specify the attributes
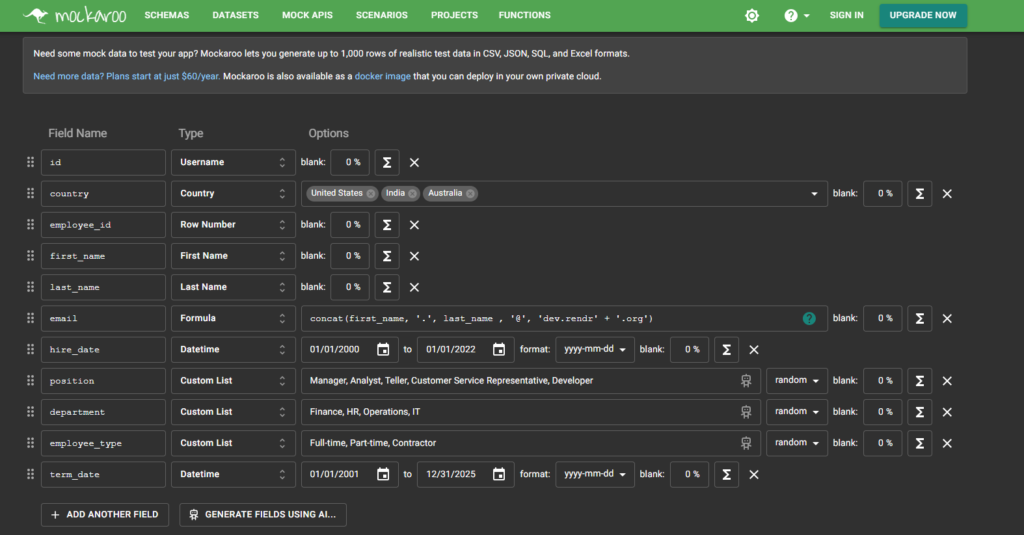
extract the data in CSV format and run the below script to generate hierarchical manager mapping for each record such that if a user belongs to a particular department and it’s designation is not manager, then she/he should be assigned to the id of the previous manager found from the same department. However, if the user has the position of manager and there was no user found previously from the same department and position as manager, keep the manager field as same as id of the user. Also, if a user is a manager and there was a previous user encountered with the same department and position as manager, set the manager as the id of the user who was the manager and from the same department
# -*- coding: utf-8 -*-
"""
Created on Fri May 24 15:54:02 2024
@author: Rendr
"""
import pandas as pd
import random
# Read the CSV data into a DataFrame
df = pd.read_csv('D://MOCK_DATA.csv')
# Initialize the manager column with None
df['manager'] = None
# Create a helper column to indicate if the employee is a manager
df['is_manager'] = df['designation'].str.lower() == 'manager'
# Sort the DataFrame by department and whether the designation is 'manager' or not
# This ensures managers are processed before other employees within each department
df.sort_values(by=['department', 'is_manager', 'id'], ascending=[True, False, True], inplace=True)
# Group the DataFrame by department
grouped = df.groupby('department')
# List to hold SQL insert statements
insert_statements = []
# Iterate through each department group
for department, group in grouped:
managers = group[group['is_manager']]['id'].tolist()
employees = group[~group['is_manager']]['id'].tolist()
# If there are no managers in the department, continue to the next department
if not managers:
continue
# Assign managers randomly to non-manager employees
for employee_id in employees:
random_manager = random.choice(managers)
df.loc[df['id'] == employee_id, 'manager'] = random_manager
# For managers, if there are multiple, randomly assign other managers to each other
for i, manager_id in enumerate(managers):
if len(managers) > 1:
other_managers = managers[:i] + managers[i+1:]
random_manager = random.choice(other_managers)
df.loc[df['id'] == manager_id, 'manager'] = random_manager
else:
# If there's only one manager, they manage themselves
df.loc[df['id'] == manager_id, 'manager'] = manager_id
# Generate SQL insert statements
for index, row in df.iterrows():
insert_statement = f"INSERT INTO employees (id,country,employee_id,first_name,last_name,email,hire_date,designation,department,employee_type,term_date,manager) VALUES ({row['id']}, {row['country']}, '{row['employee_id']}', '{row['first_name']}', '{row['last_name']}', '{row['email']}', '{row['hire_date']}', '{row['designation']}', '{row['department']}', '{row['employee_type']}', '{row['term_date']}', {row['manager']});"
insert_statements.append(insert_statement)
# Write SQL insert statements to a file
with open('D://insert_statements.sql', 'w') as file:
for statement in insert_statements:
file.write(statement + '\n')
you have to update the fields value while generating sql statement, the above script generates the sql query for MySQL DB to insert random data with manager hierarchy based on the user’s department. Below is the sample file generated by the above code when provided with inout csv file (MOCK_DATA.csv)